Batched backpropagation: connecting the code and the math
If you want to be an effective machine learning engineer, it’s a good idea to understand how frameworks like PyTorch and TensorFlow work. You don’t need to know all the details of building the framework from scratch, but you should be comfortable with building a simple neural network using low-level building blocks.
That usually goes well. You implement a linear layer, a rectifier unit, a loss function—forward pass done.
But then, you run into troubles such as:
- Dimensions stop matching.
- You don’t whether you need a matrix or element-wise multiplication.
- Code is just dead slow.
You get it working eventually, but you’re guessing half of the time.
The exact thing happened to me when I watched the first lesson of fast.ai (part 2) course. I felt comfortable until I had to implement the backward pass. I just didn’t get how the code comes from the math I knew. As Jeremy suggested in the course, I’ve read The matrix calculus you need for deep learning, but it was still unclear.
If you felt any of the the pains I’ve described or want to fully understand how to write it yourself, this guide is for you. It is written as a sidecar to the math guide. After you read it, you will fully understand how to write performant backward pass for basic neural network layers.
You can jump to a Google Collab notebook and run, change and interact with the code any way that will help you to understand the topic.
Building a neural network
To build a simple neural network, we need to build at least:
- linear layer;
- rectified unit (ReLu);
- mean square error (MSE later in the guide).
We want to build both forward and backward pass. And we’d like a modular code, please! By having a modular code, I imagine having a set of classes or functions we can compose whenever we use a particular layer. For example, I’d like to just call lin whenever I want to perform forward pass of the linear layer, regardless of the position in the network. Same for the backward pass. I’d like to call lin_grad whenever we have to calculate the gradient of the linear layer.
For the purpose of learning this, we’ll use the MNIST dataset. It doesn’t really make sense to use regression for classification problems, but MNIST is here just to serve as a dataset.
Before we dive into how this works, I suggest getting familiar with The matrix calculus guide and basic Python. If you don’t understand every detail of the math guide, that’s okay. I didn’t either before I started writing this. As I go and unroll the math, I’ll link to the relevant parts of The matrix calculus guide. The rest should be relatively easy to pick up as we go.
The forward pass is simpler and not really the topic of this blog post. Here is the code we’ll use:
def lin(X, w, b): return X@w + b
def relu(x): return x.clamp_min(0.)
def mse(output, targ): return (output.squeeze(-1) - targ).pow(2).mean()
def forward(X, targ):
l1 = lin(X, w, b)
out = relu(l1)
loss = mse(out, targ)
Clarifying what our inputs are:
- $\mathbf{X}$ (N, D)1 is a batch of inputs $\mathbf{x}$ (D, 1).
- $\mathbf{w}$ (D, 1) is the weight matrix of the linear layer.
- $\mathbf{b}$ (D) is a bias parameter of the linear layer.
- $\mathbf{targ}$ (N, 1) is a vector of expected outputs (classes).
In order to implement the gradient descent (or any similar optimization method), we have to understand how the loss function changes as parameters change. In other words, we have to calculate the gradient.
Analyzing the MSE expression
In closed form, loss function is defined as C = mse(relu(linear(X,w,b), Y).
In the python land, it looks like this:
def mse_pure_python():
errors = [error(relu(linear(x, w, b)), y) for x, y in zip(X, Y)]
return mean(errors)
It’s important to notice that MSE “breaks” the matrix X into multiple function calls for different inputs x. And it totally makes sense. Because we run a batch of inputs (X) through a neural network, each row will correspond to the result of running one vector x through a neural network.
Side note: Batches are here just to make the execution faster on GPU—they can’t change the math. The first element in the errors list is the error for the first input, the second item is the error of the second input, and so on. Notice that this isn’t true just for the last layer, but for each layer in the network!
We’ll use that to simplify the gradient calculation. In each step of the backward pass, we’ll independently calculate the gradient for each row. For example, instead of calculating the gradient of a function operating on matrix $\mathbf{X}$ (N, D), we’ll work out N gradients of a function operating on vector $\mathbf{x}$ (D, 1).
We could use the vectorized code that will do it for all rows at once. That could make the code look quite different, but it’s important to understand the semantic of each row—it’s gradient for an input vector in that position.
Decomposing the problem
Let’s take a look at the expression for one of the partial derivatives. To make sure I illustrate all the important parts, I’ve picked the gradient with respect to parameter w.
Calculating the partial derivative is explained in The matrix calculus guide. It develops into this long-ish expression:
\begin{align} \frac{\partial C(v)}{\partial \mathbf{w}} &=&\begin{cases} \vec{0}^T & \mathbf{w} \cdot \mathbf{x}_i + b \leq 0\newline \frac{2}{N} \sum_{i=1}^N (\mathbf{w}\cdot\mathbf{x}_i+b-y_i)\mathbf{x}_i^T & \mathbf{w} \cdot \mathbf{x}_i + b > 0 \end{cases} \end{align}
Directly implementing this in Python would give us the correct gradient, but it’s calculated all at once, ignoring the “modularity” property we want to achieve. It does not help us implement _grad function for each layer.
Let’s go back and start from the expression of MSE. Since we’ll calculate it input by input, we can ignore the fact that we have a batch of inputs (sort of—I’ll explain it later).
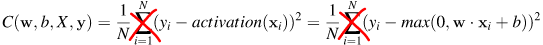
We’ll now use substitutions to break the problem down
These aren’t some random substitutions. Each substitution matches one line of code in the forward pass, and is exactly the first step you should do every time you want to write modular code—replace each layer with a new variable!
def forward(X, targ):
l1 = lin(X, w, b) # z(x, w, b)
out = relu(l1) # u(z)
loss = mse(out, targ) # C(u)
To add clarity, let’s rename these variables so the variables have the same names as in math expressions.
def forward(X, Y):
Z = lin(X, w, b)
U = relu(Z)
C = mse(U, Y)
Notice that we use capital Z and U instead of z and u. It’s because these variables will contain results for all input vectors from the batch, not just one.
Since C is a function of u now, we need to apply the chain rule to calculate $\frac{\partial C(v)}{\partial \mathbf{w}}$. $\frac{\partial C(v)}{\partial \mathbf{w}} = \frac{\partial C}{\partial \mathbf{u}} \frac{\partial u}{\partial \mathbf{z}}\frac{\partial z}{\partial \mathbf{w}}$.
So we have three components in that math expression and three _grad function calls. Each component of that multiplication will be calculated by its _grad function! mse_grad will calculate $\frac{\partial C}{\partial \mathbf{w}}$, relu_grad will calculate $\frac{\partial u}{\partial \mathbf{z}}$ and lin_grad will calculate $\frac{\partial z}{\partial \mathbf{w}}$.
Let’s combine _grad functions to create a backward pass. There are multiple ways to do that, but we’ll use one that Jeremy uses in the course that motivated this blog post (it’s also very similar to what PyTorch does).
As some _grad function finishes, it will save .g property with a gradient $\frac{\partial C}{\partial \mathbf{v}}$ for each input variable v. This rule will allow us to do a backward pass just once. At the end, all variables will have .g property.
For example, after running mse_grad(U, Y), U.g will contain $\frac{\partial C}{\partial \mathbf{u}}$. After relu_grad finishes, Z.g will contain $\frac{\partial C}{\partial \mathbf{z}}$. Notice that it’s the same as $\frac{\partial C}{\partial \mathbf{u}} \frac{\partial u}{\partial \mathbf{z}}$. Getting a gradient with respect to w will be as easy as calling w.g.
That gives us enough to define forward_and_backward function.
def forward_and_backward(X, Y):
Z = lin(X, w, b)
U = relu(Z)
C = mse(U, Y)
mse_grad(U, Y)
relu_grad(Z, U)
lin_grad(X, Z, w, b)
It’s been a long ride already, but we finally know enough to start implementing _grad functions.
mse_grad function
Mean square error (MSE) is defined by $\mathit{MSE} = C(U) = 1/N* \sum_{i=1}^N(y_i-u_i)^2 $.
Without losing correctness, we can extract the sum. That brings us to $\mathit{MSE} = C(U) = \sum_{i=1}^N1/N*(y_i-u_i)^2 $. Remember we said we’d operate on results of single input, not a batch?
If we ignore the sum for the moment and remember that we have to tackle it later, we get the MSE for each input, instead of a batched version.
$\mathit{MSE(u, y)} = 1/N * (y-u)^2.$
The gradient of that function is $\frac{\partial \mathit{MSE}}{\partial u} = \frac{\partial (\frac{1}{N} * (y-u)^2)}{\partial u} = \frac{1}{N} * 2 * (y-u) *\frac{\partial (y-u)}{\partial u} = \frac{1}{N} * 2 * (y-u) * -1 = \frac{-2}{N}(y-u)$
Now we have to aplly it for each row from $\mathbf{U}$ and return it as a float tensor.
def mse_grad_loop(U, Y):
N = len(U)
results = [-2./N*(Y[i]-U[i]) for i in range(N)]
return torch.FloatTensor(results)
But there is a more elegant way to implement that (and faster!). PyTorch has element-wise operators (*, -, +) and we should use them here. Using element-wise operators, we can write it as:
# U - input
# Y - ouput
def mse_grad(U, Y):
# grad of loss with respect to output of previous layer
N = U.shape[0]
# we have to unsqueeze Y because its' dimensions is (N) while U's is (N,1)
# not doing so would broadcast and return wrong dimensions
U.g = 2. * (Y.unsqueeze(-1)-U) / N
That’s all there is for mse_grad! We had to gloss over that “ignore the sum” part a little bit, but apart from that, everything else should be clear. If it’s not, please refer to this section of The matrix calculus guide.
Before we move on, let’s see how far we got with the gradient: $\frac{\partial \mathit{MSE}}{\partial \mathbf{w}} = \frac{\partial \mathit{MSE}}{\partial \mathit{u}}\frac{\partial \mathit{u}}{\partial \mathbf{w}} = \sum_{i=1}^{N}{\frac{-2}{N}(y-u))\frac{\partial u}{\partial \mathbf{w}}}$
relu_grad function
relu_grad is responsible for calculating $\frac{\partial u}{\partial z}$ and saving $\frac{\partial MSE}{\partial z}$ into Z.g.
If we take a look at the graph and definition of relu function, we can see that the gradient for all points before 0 is 0, and for all points after 0 it’s 1.
Mathematically defined \[\frac{\partial u}{\partial z} = \begin{cases} 0 & z \leq 0\newline 1 & z > 0 \end{cases}\]
We have to apply that function to each row (again, each row matches one input $\mathbf{x}$). PyTorch’s operator > 0 makes it really easy. If an element of a tensor is bigger than 0, it will be True, otherwise False. Calling .float() on such tensor will turn Falses and Trues exactly into 0s and 1s, which is what we need.
# Z - input
# U - ouput
def relu_grad(Z, U):
# grad of relu with respect to output of previous layer
du_dz = (Z > 0).float()
dC_du = U.g
dC_dz = dC_du * du_dz
Z.g = dC_dz
Checking the progress of $\frac{\partial \mathbf{C}}{\partial \mathbf{w}}$: \[ \frac{\partial \mathit{MSE}}{\partial \mathbf{w}} = \frac{\partial \mathit{MSE}}{\partial \mathit{u}}\frac{\partial \mathit{u}}{\partial \mathbf{w}} = \sum_{i=1}^{N}{\frac{-2}{N}(y-u))\frac{\partial u}{\partial z}\frac{\partial z}{\partial \mathbf{w}}} = \sum_{i=1}^{N}{\frac{-2}{N}(y-u)\bigg(\begin{cases} 0 & z \leq 0\newline 1 & z > 0 \end{cases}\bigg)\frac{\partial z}{\partial \mathbf{w}}} \]
lin_grad function
Gradient with respect to w
To calculate the gradient with respect to w, we have to take a look at the implementation of the forward pass: $\mathbf{X}\mathbf{w} + \mathbf{b}$. Just like in every step of the backward pass, we have to tackle the gradient input by input (row by row). The function applied to each input $\mathbf{x}$ is $\mathbf{w}\cdot\mathbf{x} + b$.
The derivative of that fn with respect to w is x_t.
Now, if you remember the vector chain rule, you may remember that, when working with vectors, we actually have to perform matrix multiplication of Jacobians. Let’s calculate the gradient row by row and stack it together.
# Z - output
def lin_grad(X, Z, w, b):
n = X.shape[0]
result_per_row = []
for i in range(n):
result_per_row.append(Z.g[i] @ X[i].unsqueeze(0))
# we have to unsqueeze just because of how @ is implementes for [1]@[1xN]
stacked = torch.stack(result_per_row).unsqueeze(-1)
w.g = stacked
And we’re done with gradient with respect to $\mathbf{w}$! We have multiplied $\frac{\partial \mathit{MSE}}{\partial z}\frac{\partial z}{\partial \mathbf{w}}$ and got $\frac{\partial \mathit{MSE}}{\partial \mathbf{w}}$, which is what we were initially trying to do.
Well, almost! We never put that sum anywhere! We’ll sum the gradients across the 0th dimension (the one matching the number of inputs we have).
# Z - output
def lin_grad(X, Z, w, b):
n = X.shape[0]
result_per_row = []
for i in range(n):
result_per_row.append(Z.g[i] @ X[i].unsqueeze(0))
# we have to unsqueeze just because of how @ is implementes for [1]@[1xN]
stacked = torch.stack(result_per_row).unsqueeze(-1)
w.g = stacked.sum(0) # now summed!
print(w.shape, w.g.shape)
This is the first time we’ve implemented all the functions so we can run forward_and_backward_pass. Running it prints shapes of w and w.g.
forward_and_backward(x_train, y_train)
torch.Size([784, 1]) torch.Size([784, 1])
They match. It means we’re doing something right!
But how do you know when to sum the gradients?
It could seem that we’ve cheated a bit by running a sum when we need it, but not really understanding whether it will result in composable components. Not quite!
There are two reasons why we run the sum now:
- w is a parameter. It’s the end of the calculation for that gradient.
- If you expand the original sum we ignored, you’ll see that our vector w is part of every component under the sum sign. Also, it’s important to understand why it’s always the sum (towards the end of the section).
Here is something interesting. Let’s see the gradient calculated so far.
\[ \begin{align} \frac{\partial \mathit{MSE}}{\partial \mathbf{w}} &= \frac{\partial \mathit{MSE}}{\partial \mathit{u}}\frac{\partial \mathit{u}}{\partial \mathbf{w}} \newline &= \sum_{i=1}^{N}{\frac{-2}{N}(y-u))\frac{\partial u}{\partial z}\frac{\partial z}{\partial \mathbf{w}}} \newline &= \sum_{i=1}^{N}{\frac{-2}{N}(y-u)\bigg(\begin{cases} 0 & z \leq 0\newline 1 & z > 0 \end{cases}\bigg)\frac{\partial z}{\partial \mathbf{w}}} \newline &= \sum_{i=1}^{N}{\frac{-2}{N}(y-u)\bigg(\begin{cases} 0 & z \leq 0\newline 1 & z > 0 \end{cases}\bigg)x_i^T} \end{align} \]
Let’s get rid of $u$ and $z$. We’ve previously defined them as $z(\mathbf{w}, \mathbf{x}, b) = \mathbf{w}\cdot\mathbf{x} + b$ and $u(z) = max(0, z)$. Replacing $u$ and $z$ with their values gives us
\[ \frac{\partial \mathit{MSE}}{\partial \mathbf{w}} = \sum_{i=1}^{N}{\frac{-2}{N}(y-max(0, \mathbf{w}\cdot\mathbf{x} + b))\bigg(\begin{cases} 0 & {\mathbf{w}\cdot\mathbf{x} + b} \leq 0\newline 1 & {\mathbf{w}\cdot\mathbf{x} + b} > 0 \end{cases}\bigg)x_i^T} \]
Multiplying these 3 components and bringing the “0/rest” switch that came from relu gives us:
Looks familiar? Well, it’s exactly the same as the one in The matrix calculus guide! Let’s finish lin_grad.
Other gradients
The same rule applies for gradients with respect to the input and b parameters. Partial derivative with respect to b is easier—it is 1. Don’t forget to add the sum (same reasoning as for w parameter).
# Z - output
def lin_grad(X, Z, w, b):
n = X.shape[0]
result_per_row = []
for i in range(n):
result_per_row.append(Z.g[i] @ X[i].unsqueeze(0))
# we have to unsqueeze just because of how @ is implementes for [1]@[1xN]
stacked = torch.stack(result_per_row).unsqueeze(-1)
w.g = stacked.sum(0)
b.g = Z.g.sum(0)
Calculating the gradient with respect to $\mathbf{x}$ is similar. $\frac{\partial (\mathbf{w}\cdot\mathbf{x}+b)}{\partial x} = w_t$. It means the gradient is a tensor stacking $\mathbf{w^T}$ for each input $\mathbf{x}$.
# Z - output
def lin_grad(X, Z, w, b):
n = X.shape[0]
result_per_row = []
for i in range(n):
result_per_row.append(Z.g[i] @ X[i].unsqueeze(0))
# we have to unsqueeze just because of how @ is implementes for [1]@[1xN]
stacked = torch.stack(result_per_row).unsqueeze(-1)
w.g = stacked.sum(0)
b.g = Z.g.sum(0)
# now with
n = X.shape[0]
result_per_row = []
for i in range(n):
result_per_row.append(Z.g[i] @ w.t())
stacked = torch.stack(result_per_row)
X.g = stacked
That’s it! We’ve implemented a small neural network. And we can fully understand how it relates to the math!
Optimizing the code
If you run that code, you’ll see it’s quite slow.
%%time
forward_and_backward(x_train, y_train)
CPU times: user 13.5 s, sys: 1.09 s, total: 14.6 s
Wall time: 2.46 s
It took 2.46 seconds for a batch of 50,000 inputs. Running a gradient descent runs the function tens of times, which means the training of this trivial network could take hours. In my experience, PyTorch does far better. The reason is that the lin_grad we’ve implemented here is far slower than it could be.
If you look at what we’re really doing to calculate gradient with respect to w, you can see that we multiply each x.t with some number from Z.g. We then sum all these numbers. That set of operations sounds very familiar.
It’s a matrix multiplication! You can see that it’s summing along dimension N, which means that it will be inner dimension in the matrix multiplication. We can rewrite the code as X.t() @ out.g.
# Z - output
def lin_grad(X, Z, w, b):
w.g = X.t() @ Z.g # now far faster
b.g = Z.g.sum(0)
# now with
n = X.shape[0]
result_per_row = []
for i in range(n):
result_per_row.append(Z.g[i] @ w.t())
stacked = torch.stack(result_per_row)
X.g = stacked
Let’s measure the time again!
%%time
forward_and_backward(x_train, y_train)
CPU times: user 6.84 s, sys: 556 ms, total: 7.39 s
Wall time: 1.27 s
It’s definitely faster. Let’s see whether we can optimize it further.
If we look at the code of calculating the gradient with respect to input, we can see that we’re doing something similar. out.g is of shape [Nx1] and our partial derivative w_t is of shape [1xD]. Multiplying each row of out.g with w_t is identical to matrix multiplicaiton of two matrices. We can rewrite it as out.g @ w.t().
# Z - output
def lin_grad(X, Z, w, b):
w.g = X.t() @ Z.g # now far faster
b.g = Z.g.sum(0)
X.g = Z.g @ w.t()
We could rewrite the b.g calculation in a similar way, but the performance gain is far smaller.
Let’s measure the execution time again.
%%time
forward_and_backward(x_train, y_train)
CPU times: user 535 ms, sys: 515 ms, total: 1.05 s
Wall time: 33.4 ms
Sounds more like what we see when we use PyTorch’s classes.
Bonus: a more powerful linear layer
Linear layer we’ve implemented has a very simple shape of the parameter matrix w [Dx1]. It transforms each input vector x into one number (i.e. one feature). Such a simple linear layer is not very powerful.
We usually want to transform input vector x [Dx1] into a number of features [Mx1]. To do that, we have to replace vector w of size [Dx1] with a matrix W [DxM]. The whole math is explained in this useful paper from Stanford. What’s really nice is that we don’t have to change the code at all. Linear layer we’ve implemented is ready for such W matrices already!
-
(N, D) just means that there are N rows and D rows. Stricter mathematical notation would be $X \in \mathcal{R}^{NxD}$. ↩